本地部署大模型不仅能保障数据隐私,还能降低调用成本;而微调则能让通用大模型适配特定场景(如行业问答、风格化创作)。本文以 Meta 的 Llama-3 为例,完成本地部署与 Lora 微调全流程。
大模型与传统神经网络
大模型为何能处理复杂任务(如长文本理解、多轮对话),其与传统神经网络的核心差异 —— 架构革新。
传统神经网络
传统神经网络(如 CNN、RNN)在处理序列数据时存在明显短板:
- CNN(卷积神经网络):通过卷积核 “局部感知”,擅长图像等结构化数据,但对长文本(如 1000 字以上的文章)的 “全局关联” 捕捉能力弱(需多次卷积叠加,易丢失长距离信息);
- RNN(循环神经网络):虽能按 “时序顺序” 处理序列(如文本),但存在 “梯度消失 / 爆炸” 问题 —— 处理长序列(如 500token 以上)时,早期信息会被稀释,且无法并行计算(前一时刻输出需作为后一时刻输入),效率极低。
Transformer 架构:大模型的 “发动机”
2017 年,Google 团队在《Attention Is All You Need》中提出的Transformer 架构,彻底突破了上述瓶颈。其核心是 “自注意力机制”,让模型能 “全局感知” 序列中每个元素的关联,且支持并行计算。
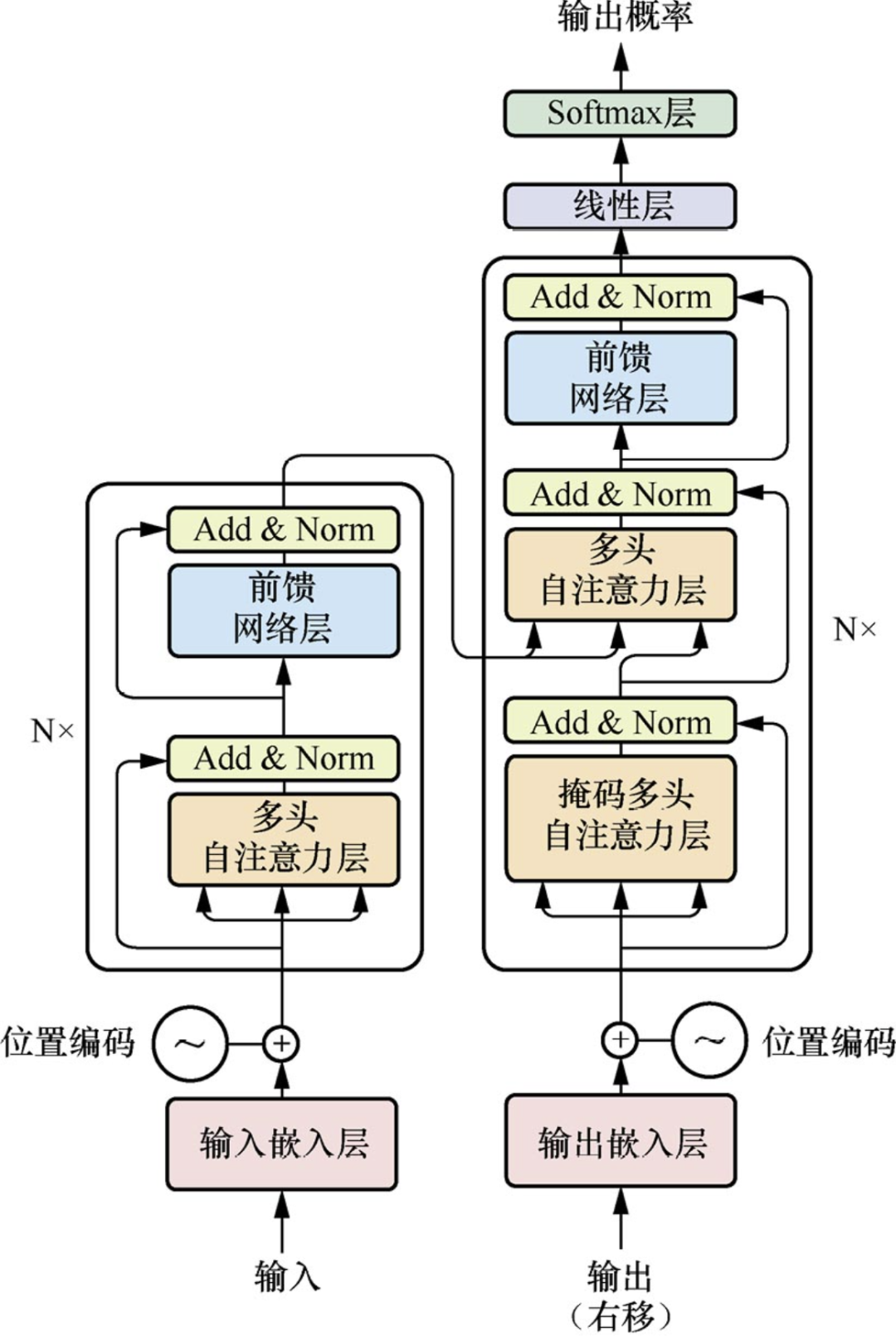
自注意力机制(Self-Attention)
传统 RNN 按 “时序” 逐个处理 token,而自注意力机制可同时计算每个 token 与其他所有 token 的 “关联权重”。例如处理 “小明喜欢吃苹果,他每天都买” 时,模型能通过权重计算直接关联 “他” 与 “小明”,无需依赖时序顺序。
计算公式中,通过 Query(查询)、Key(键)、Value(值)矩阵计算注意力权重:
\(Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\)
\(d_k\)为 Key 的维度,避免权重矩阵过大导致梯度不稳定
Encoder-Decoder 结构
Transformer 由 “Encoder(编码器)” 和 “Decoder(解码器)” 组成:
- Encoder:负责 “理解输入”(如将文本转换为语义向量),通过多层自注意力 + 前馈网络,捕捉输入序列的全局特征;
- Decoder:负责 “生成输出”(如根据输入生成回答),除自注意力外,还通过 “交叉注意力” 关联 Encoder 的输出,确保生成内容与输入对齐。
并行计算能力
自注意力机制无需依赖时序,可同时处理所有 token,配合 GPU 的并行计算能力,让模型能高效训练 “亿级 / 千亿级参数”—— 这也是大模型能实现 “复杂语义理解” 的基础。
Mata开源大模型Llama-3
Llama-3 是 Meta 在 2024 年推出的开源大模型系列,目前已发布 8B(80 亿参数)、70B(700 亿参数)等版本,凭借 “性能强、适配性高” 成为本地部署的热门选择。相比 Llama-2,训练数据量提升 40%,涵盖多语言(支持 26 种语言)、多领域(代码、科学文献等),基础语义理解能力更强;并且微调了 Transformer 的注意力层(如调整 q/k/v 投影矩阵维度),在相同参数下,推理速度提升 15%;
Instruct 版本(如 Meta-Llama-3-8B-Instruct)是在基础版上经过 “指令微调(SFT)” 的版本 —— 通过大量 “人类指令 – 回答” 数据(如 “用户问 XX,模型应答 XX”)训练,让模型能精准理解人类意图。
本地部署
硬件选择
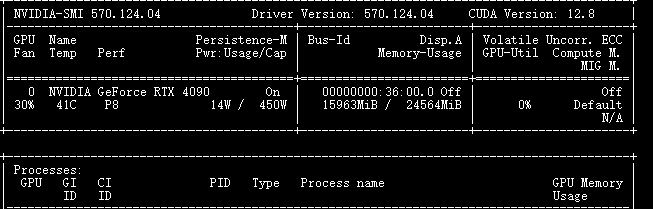
大模型部署的核心限制是 “显存”—— 模型加载时需将参数、梯度等数据存入 GPU 显存。以 8B-Instruct 版本为例:
- 参数规模:80 亿参数,若按 “半精度(float16)” 存储(每个参数占 2 字节),仅参数就需:8e9 × 2 字节 = 16e9 字节 ≈ 16GB 显存;
- 额外开销:推理时还需存储输入 token、中间计算结果等,约需 4-6GB 显存;
- 总需求:16+6=22GB 显存。
4090 单卡显存为 24GB,刚好覆盖需求;若用 3090(24GB 显存)也可,但 4090 的 CUDA 核心更多,推理速度更快(相同输入下,生成 100token 的时间比 3090 少 20%)。若显存不足(如 3060 12GB),可通过 “4bit 量化” 将显存需求压至 8-10GB(后续微调部分会讲)。

环境配置
目前算力平台基本提供了基础镜像的安装,还是很方便的。如autodl提供基础镜像:
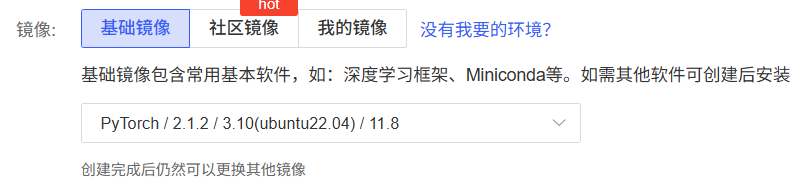
- 系统:Ubuntu 22.04
- Python:3.10(大模型工具链兼容性最佳)
- PyTorch:2.1.2(支持 Flash Attention,加速推理)
- CUDA:11.8(4090 需 CUDA 11.7+,11.8 稳定性更优)
一些算力平台也默认提供conda工具,自己安装conda也比较简单
# 根目录
cd ~
# 获取conda安装包
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
# 执行权限
chmod +x Anaconda3-2024.10-1-Linux-x86_64.sh
# 执行安装
./Anaconda3-2024.10-1-Linux-x86_64.sh
# 安装完成后,使环境变量生效
source .bashrc
# 创建conda环境
conda create -n llama3 python=3.10 -y
conda activate llama3
# 安装PyTorch(需匹配CUDA 11.8)
pip3 install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu118
# 安装模型加载与部署依赖
pip install transformers==4.38.2 accelerate==0.27.2 modelscope==1.9.5 # modelscope用于下载模型
pip install sentencepiece # Llama-3分词器依赖模型下载:从魔搭获取 Llama-3
Llama-3 需通过官方渠道获取授权,但国内可通过 “魔搭社区(ModelScope)” 下载适配后的 Instruct 版本。
from modelscope import snapshot_download
# 下载模型到本地(cache_dir为下载路径)
model_dir = snapshot_download(
'LLM-Research/Meta-Llama-3-8B-Instruct',
cache_dir='/root/autodl-tmp'
)
print(f"模型下载完成,路径:{model_dir}")
下载完成后,模型文件(含权重、分词器配置等)会保存在/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct。
部署测试:“who are you?”
从本地加载模型,测试基础对话功能:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# 模型路径
model_path = "/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct"
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path)
tokenizer.pad_token = tokenizer.eos_token # 设置pad token(Llama默认无pad token)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype="auto",
load_in_4bit=False, # 不启用4bit量化
trust_remote_code=True
)
# 创建对话管道
chat_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512 # 生成文本最大长度
)
# 测试对话
user_input = "who are you?"
messages = [{"role": "user", "content": user_input}]
response = chat_pipeline(messages)
output = response[0]["generated_text"][-1] # 提取模型回答
print("-"*50)
print(f"用户查询:{user_input}")
print(f"Llama回答:\n{output}")
print("-"*50)若能正常输出,说明部署成功!模型输出:

Lora 微调:让 Llama-3 “学梗”
部署只是第一步,微调能让模型 “个性化”—— 比如让 Llama-3 学会 “弱智吧” 的幽默回答风格(如 “为什么水开了会冒泡?因为它在学可乐生气”)。本文采用Lora 微调(低秩适应),无需全量训练模型,显存占用低、效果好。
微调基础
什么是 SFT ?
SFT(Supervised Fine-Tuning,有监督微调)是大模型对齐人类意图的核心手段:通过 “标注数据”(如 “用户问 XX,理想回答是 XX”)训练模型,让其输出更符合需求。例如用 “弱智吧” 的 “问题 – 搞笑回答” 数据微调,模型就能学会类似风格。
什么是 Lora ?
全量微调需更新模型所有参数(8B 模型约 80 亿参数),显存需求极高(8B 全量微调需至少 40GB 显存)。而Lora 微调通过 “冻结预训练模型权重,仅训练低秩矩阵” 大幅降低成本:
- 原理:在 Transformer 的注意力层(如 q_proj、v_proj)中,给权重矩阵W添加低秩矩阵\(W_A\)(输入投影)和\(W_B\)(输出投影),训练时仅更新\(W_A\)和\(W_B\)(秩r通常设为 8-32,远小于原矩阵维度);
- 优势:显存占用仅为全量微调的 1/10(8B 模型 Lora 微调需 8-12GB 显存),且微调后可导出小体积的 Lora 权重(仅几十 MB),方便部署。
实战:用 “弱智吧” 数据集微调 Llama-3
数据集下载
“弱智吧” 数据集包含大量搞笑问答,可以用来微调,让Llama变弱智幽默诙谐。魔搭上有相关数据集可以下载:
from modelscope.msdatasets import MsDataset
# 下载数据集
ds = MsDataset.load('nullskymc/ruozhiba_R1', subset_name='default', split='train')
数据集遵循以下格式:
{
"instruction": "······",
"input": "······",
"output": "······"
}Lora微调
原本计划用纯 Lora 微调,但 8B 模型即使冻结主权重,加载时仍需约 16GB 显存(float16),加上训练时的梯度、优化器状态,24GB 显存会 “卡满”。因此改用QLoRA(量化 Lora):先将模型量化为 4bit(显存压至 4-5GB),再叠加 Lora,24GB 显存轻松运行。
import torch
from datasets import load_dataset
from trl import SFTTrainer
from peft import LoraConfig, get_peft_model
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
BitsAndBytesConfig
)
# 路径配置
model_path = "/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct" # 模型路径
data_path = "/path_to_your_dataset" # 数据集路径
# 1. 加载数据集
dataset = load_dataset("json", data_files=data_path)["train"]
# 2. 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path)
tokenizer.pad_token = tokenizer.eos_token # 设置pad token
# 3. 4bit量化配置(核心:降低显存占用)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 4bit加载模型
bnb_4bit_use_double_quant=True, # 双量化(进一步降低误差)
bnb_4bit_quant_type="nf4", # 量化类型(nf4比fp4更适合大模型)
bnb_4bit_compute_dtype=torch.bfloat16 # 计算时用bfloat16(精度更高)
)
# 4. 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
# 5. Lora参数配置(核心:决定微调效果)
lora_config = LoraConfig(
r=16, # 秩(r越大,微调能力越强,但显存占用越高,建议8-32)
lora_alpha=32, # 缩放因子(alpha/r决定学习率缩放)
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"], # Llama-3的注意力层(需对应模型结构)
lora_dropout=0.05, # dropout防止过拟合
bias="none", # 不训练偏置项
task_type="CAUSAL_LM" # 因果语言模型任务
)
model = get_peft_model(model, lora_config) # 给模型添加Lora适配器
# 6. 确认可训练参数(仅Lora相关参数)
model.print_trainable_parameters() # 输出:可训练参数占比(通常<1%)
# 7. 训练参数配置
training_args = TrainingArguments(
output_dir="./llama3-lora-ruozhiba", # 输出路径
per_device_train_batch_size=1, # 单设备batch size(显存小就设1)
gradient_accumulation_steps=8, # 梯度累积(等效batch size=8)
learning_rate=2e-4, # 学习率(Lora微调建议1e-4~3e-4)
num_train_epochs=3, # 训练轮次(数据集小就多训几轮)
logging_steps=10, # 每10步打一次日志
save_strategy="epoch", # 每轮保存一次模型
bf16=True, # 用bfloat16加速训练
optim="paged_adamw_8bit", # 8bit优化器(进一步降显存)
report_to="none", # 不启用wandb等日志工具
)
# 8. 初始化SFT Trainer
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
dataset_text_field="instruction", # 数据集文本字段(按实际数据调整)
max_seq_length=768, # 最大序列长度(避免显存溢出)
tokenizer=tokenizer,
args=training_args,
packing=False # 不启用数据打包(简化流程)
)
# 9. 开始训练
torch.cuda.empty_cache() # 清理显存
trainer.train()
# 10. 保存Lora权重
model.save_pretrained("./llama3-lora-ruozhiba-final")关键点:
r=16:Lora 的秩,若想增强微调效果可增至 32(显存增加约 2GB);gradient_accumulation_steps=8:小 batch size + 梯度累积,平衡显存与训练效率;4bit量化:是本代码能在 4090 上运行的核心,若用 3090 等 24GB 卡,此配置必加。
Llama学会玩梗了吗?
加载基础模型 + Lora 权重,测试:
import torch
from peft import PeftModel
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
GenerationConfig
)
# 路径配置
base_model_path = "/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct"
lora_path = "./llama3-lora-ruozhiba-final" # 微调后的Lora权重路径
# 1. 加载基础模型和分词器
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
base_model = AutoModelForCausalLM.from_pretrained(
base_model_path,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
# 2. 加载Lora权重(合并到基础模型)
model = PeftModel.from_pretrained(base_model, lora_path, device_map="auto")
model.eval() # 切换到推理模式
# 3. 定义生成函数(按Llama-3格式构造输入)
def generate(query: str) -> str:
# 构造输入格式(与微调时一致,否则效果差)
prompt = f"""<|begin_of_text|>
<|start_header_id|>user<|end_header_id|>
{query}
<|start_header_id|>assistant<|end_header_id|>
"""
inputs = tokenizer(prompt, return_tensors="pt", padding=True, truncation=True, max_length=1024).to("cuda")
# 生成配置
generation_config = GenerationConfig(
max_new_tokens=200,
temperature=0.7, # 随机性(0.7适合幽默风格)
top_p=0.9,
do_sample=True,
repetition_penalty=1.1 # 避免重复
)
# 生成回答
with torch.no_grad():
outputs = model.generate(** inputs, generation_config=generation_config)
# 提取回答(过滤输入部分)
full_output = tokenizer.decode(outputs[0], skip_special_tokens=False)
response = full_output.split("<|start_header_id|>assistant<|end_header_id|>\n\n")[-1]
return response.replace("<|end_of_text|>", "").strip()
# 4. 测试
test_queries = [
"得了灰指甲,一个传染俩,问我怎么办?马上用指甲油"
]
for query in test_queries:
print(f"用户查询:{query}")
print(f"Llama回答:{generate(query)}\n" + "-"*50)模型生成对比
- 微调前:
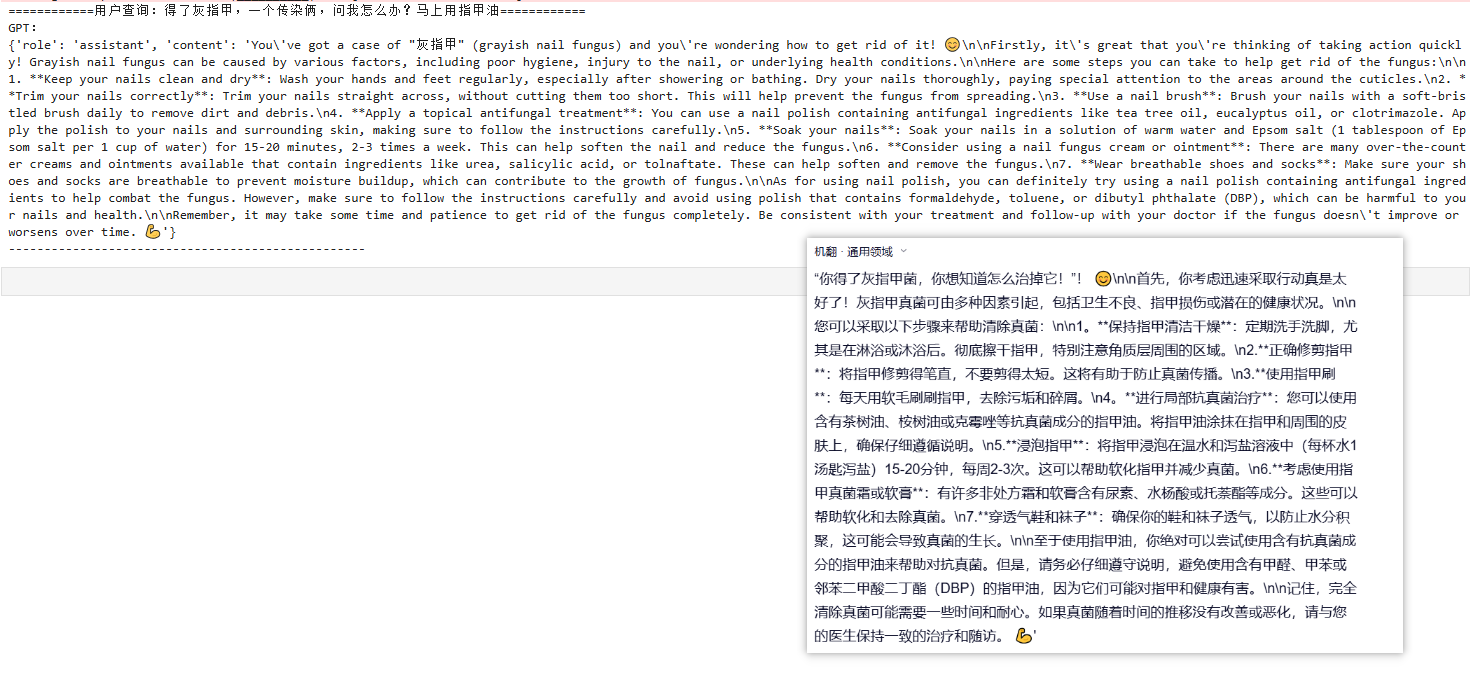
- 微调后:

参考链接
- PEFT(Lora 工具)文档:https://huggingface.co/docs/peft/index
- TRL(SFT Trainer)文档:https://huggingface.co/docs/trl/index
- Meta Llama-3 官方文档:https://ai.meta.com/resources/models-and-libraries/llama-downloads/