背景
最近在学习开发Thrift-Web工程和倒排索引,构建了一个检索引擎服务,架构图如下:
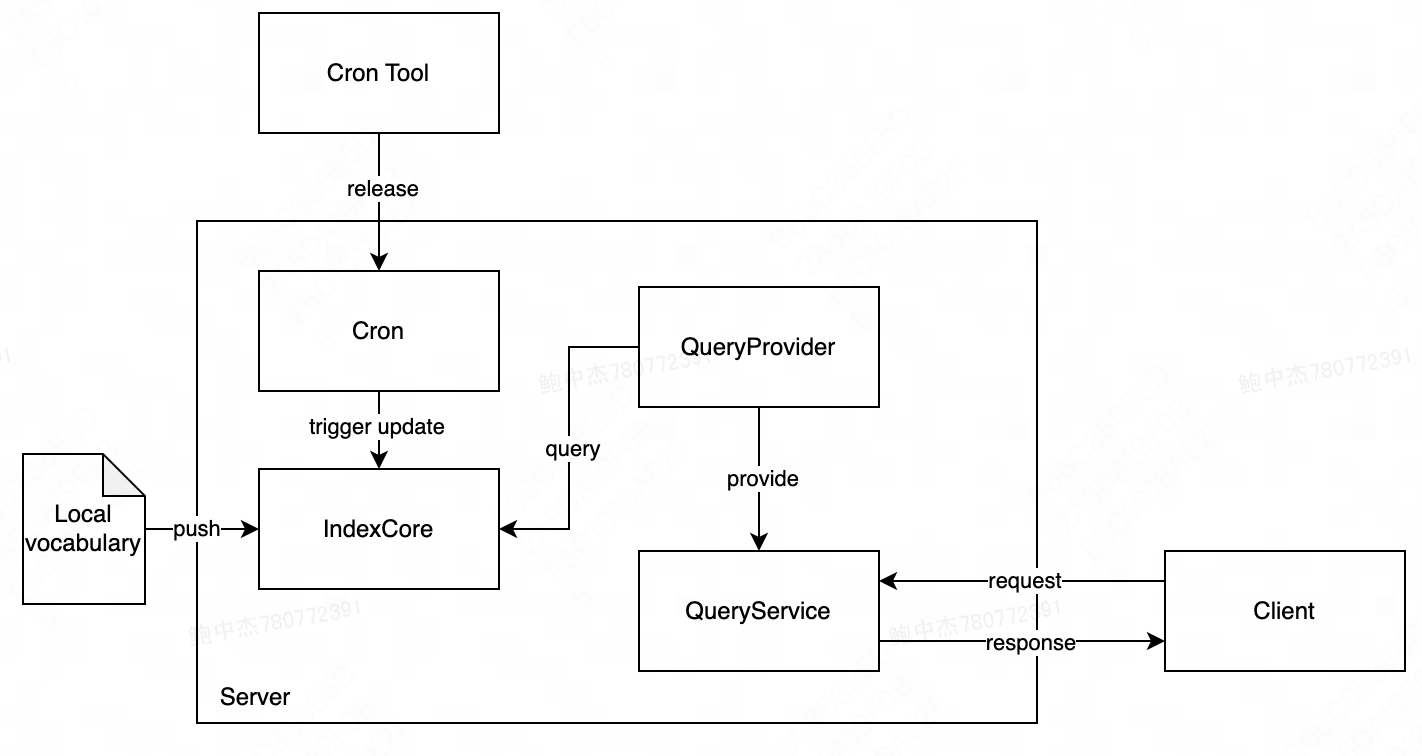
Client:客户端,mock服务的请求
QueryService:Thrift接口,对外提供检索服务
QueryProvider:检索条件过滤、实现检索功能
IndexCore:初始化构建、维护、更新倒排索引
Local Vocabulary:本地词表(索引更新时,IndexCore 从词表中获取最新的数据)
Cron:定时任务(每隔 5 min,触发索引更新)
基本概念
倒排索引
倒排索引(Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
一般在生成环境中,由于数据量高达几千万,初始化构建倒排索引或者全量更新倒排索引是非常耗时的任务,更新索引结构更多地选择是增量更新。
死锁
死锁是指两个或两个以上的进程或线程在执行过程中,由于竞争资源或互相等待对方释放资源,导致彼此都无法继续执行下去的状态。一般有四个必要条件:
- 互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
- 请求和保持条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
- 不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
- 环路等待条件:指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源
OOM
OOM (Out of Memory) 是指程序在申请内存时,没有足够的内存可供分配,导致程序崩溃或停止运行的错误。可能的原因一般有:
- 内存不足:给应用程序分配的内存太小,只能通过增大内存来解决.
- 内存泄漏:有一部分内存”无用”了,但是因为编码问题导致的没有被垃圾回收掉,产生了泄漏,最终导致了内存溢出(OOM).
当JVM因为没有足够的内存来为对象分配空间并且垃圾回收器也已经没有空间可回收时,就会抛出这个error(注:非exception,因为这个问题已经严重到不足以被应用处理)
日志上的表现一般有两种:
- java.lang.OutOfMemoryError: Java heap space
- 线程堆积:新请求持续进入系统,每个需要访问索引的请求都会创建新线程或从线程池获取线程
- 线程栈内存:每个Java线程默认占用512KB-1MB的栈内存
- java.lang.OutOfMemoryError: unable to create new native thread
- 请求对象积压:每个被阻塞的请求都会保留其关联的对象
- 临时数据结构:处理请求过程中创建的临时对象无法被释放
- 内存泄漏:被阻塞线程引用的对象无法被垃圾回收
事故现场
告警

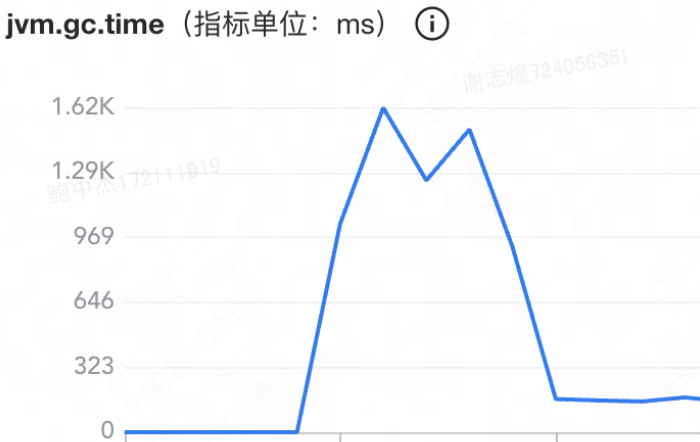
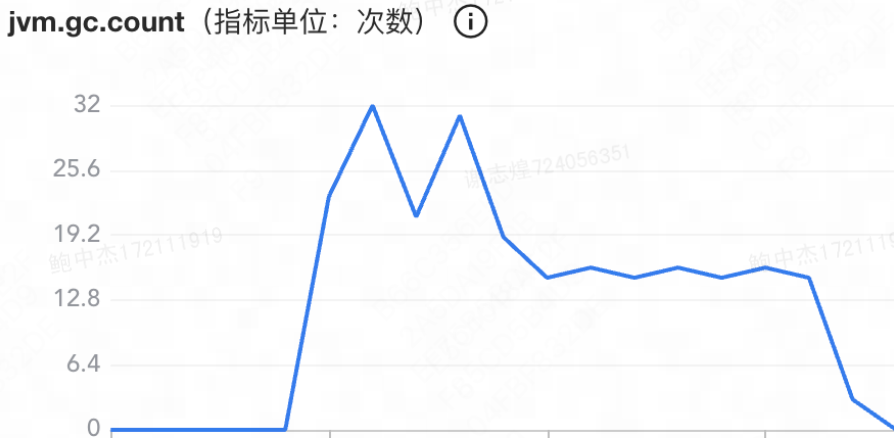
GC
排查过程
日志
检查服务运行日志,存在大量线程阻塞日志,有业务逻辑重试次数增加
容器监控
查看容器监控,发现堆内存使用量激增,GC次数增加,full GC耗时显著增加
Heap Dump
分析堆转储文件(heap dump),确定占用内存最多的类或对象,与锁的逻辑有关,线程栈问题,大量线程处于等待或阻塞状态
定位原因
/**
* 更新索引
*/
public void updateReverseIndex() {
try {
log.info("索引更新开始。");
try {
wLock.lock();
Map<String, ConcurrentSkipListSet<Spu>> updateReverseIndex = indexBuilder.buildReverseIndex();
log.info("索引更新成功。");
} catch (InterruptException e) {
log.error("索引更新失败", e);
} finally {
wLock.unlock();
}
} catch (Exception e) {
throw new QueryException(QueryResultEnum.UPDATE_INDEX_EXCEPTION);
}
}indexBuilder.buildReverseIndex()用于索引的更新,这个过程相对来说是非常耗时的,在上述场景中Thread1调用buildReverseIndex()方法发生了阻塞,而其他读索引的请求使用tryLock()方法获取读锁时,由于Thread1持有写锁,所以读锁的获取也被阻塞,这就发生了死锁。其实准确来说,这不是典型的死锁,而是”锁泄露”。利用JConsole检测,并不会检测到这种“死锁”。
再者,在QPS较高时,大量请求进入服务,每个需要访问索引的请求都会创建新线程或从线程池获取线程,并且因为拿不到读锁而阻塞,被阻塞线程引用的对象无法被垃圾回收,最终导致堆内存耗尽发生OOM。
解决方案
锁的获取与释放
锁的获取:需要使用带超时时间的tryLock()方法,当在超时时间内获取不到锁直接返回false,避免长时间阻塞
boolean locked = wLock.tryLock(timeout, TimeUnit.SECONDS);
if (locked) {
try {
// 操作索引...
} finally {
wLock.unlock();
}
}
或者使用可中断锁。不可中断锁的问题是,当出现“异常”时,只能一直阻塞等待,使用了 lockInterruptibly 方法就可以在一段时间之后,判断它是否还在阻塞,如果结果为真,就可以直接中断。
try {
wLock.lockInterruptibly(); // 允许线程中断
try {
// 操作索引
} finally {
wLock.unlock();
}
} catch (InterruptedException e) {
// 处理中断
}
锁的释放:锁的操作一定要使用try-finally块,并将锁的释放置于finally块中,即使下面这种方式也是有问题的:
wLock.lock();
try {
// 这里发生永久阻塞
waitForeverOperation();
// 永远不会执行到这里
reverseIndex = updateReverseIndex;
} finally {
wLock.unlock(); // 这行代码永远不会被执行
}
无锁
上述场景的发生是因为死锁间接导致的,除了避免死锁还有没有别的方法呢?
有的,无锁。
说是无锁,实际上只是没有“显式”的锁操作,而是使用CAS自旋。
CAS
CAS自旋锁是一种乐观锁,且天生免疫死锁,原理如下:
有这样三个值:
- V:要更新的变量(var)
- E:预期值(expected)
- N:新值(new)
CAS比较并交换的过程如下:
判断 V 是否等于 E,如果等于,将 V 的值设置为 N;如果不等,说明已经有其它线程更新了 V,于是当前线程放弃更新,什么都不做。
双索引
为了使用CAS,需要保证内存中事先准备好了新值,也就是说,IndexCore模块需要至少维护两个索引,一个是旧索引,供读请求使用,不再使用读锁进行同步,来者不拒;一个新索引异步地去更新索引并保存。当索引更新时,使用CAS自旋锁原子性地切换索引即可。代码如下:
/**
* 更新索引
*/
public void updateReverseIndex() {
try {
log.info("索引更新开始");
long start = System.currentTimeMillis();
Map<String, ConcurrentSkipListSet<Spu>> newIndex = buildNewIndexAsync().get();
// CAS 原子切换索引
Map<String, ConcurrentSkipListSet<Spu>> oldIndex = currentIndex.getAndSet(newIndex);
// 旧索引清理
oldIndex.clear();
log.info("索引更新成功,耗时:{}ms", System.currentTimeMillis() - start);
} catch (Exception e) {
log.error("索引更新异常", e);
throw new QueryException(QueryResultEnum.UPDATE_INDEX_EXCEPTION);
}
}
/**
* 异步构建
*
*/
private CompletableFuture<Map<String, ConcurrentSkipListSet<Spu>>> buildNewIndexAsync() {
return CompletableFuture.supplyAsync(() -> {
try {
return indexBuilder.buildReverseIndex();
} catch (OutOfMemoryError e) {
throw new QueryException(QueryResultEnum.OUT_OF_MEMORY_EXCEPTION);
}
}, indexBuildExecutor);
}其中,新索引构建的异步回调可以加入超时时间
newIndex = buildNewIndexAsync().get(timeout, TimeUnit.SECONDS);重新压测,问题解决,无OOM发生,系统指标和业务指标正常。